

以前の記事で、Pythonで機械学習を実装するためにはいくつかのライブラリが必要だと言いましたが、今回はそれらのライブラリについて使用例を交えて説明します。

本記事で説明するライブラリは以下のやつらです。
mglearnは必須ではないですが、本ブログで使用するので載せてます。
| ツール | 説明 |
| scikit-learn | 最先端の機械学習アルゴリズムが詰まっている最も重要なライブラリ |
| NumPy | Python用の線形代数やフーリエ変換など高レベルの数学関数ライブラリ |
| SciPy | Python用の信号処理や統計分布などの高機能ライブラリ |
| matplotlib | Python用のグラフ描画ライブラリ |
| pandas | データを変換したり解析したりするためのライブラリ |
| mglearn | グラフ描画やデータ読込でソースコードをコンパクトにするライブラリ |
scikit-learn
scikit-learnはPythonのオープンソース機械学習ライブラリです。
常に開発と改良が続けられており、最先端の機械学習アルゴリズムが用意されています。
ちなみに読み方は「サイキット・ラーン」です。
NumPy
NumPyはPythonで科学技術計算をする際の基本的なツールの1つです。
scikit-learnで使用するデータはNumPyの配列にしなければいけません。
ちなみに読み方は「ナンパイ」です。そして、Numerical Pythonの略です。
NumPy配列の使用例
NumPy配列の使用例を見ていきましょう。
import numpy as np
x = np.array([[1, 2, 3], [4, 5, 6]])
print("x:\n{}".format(x))
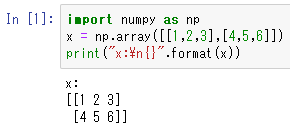
1行目は、numpyライブラリを「np」っていう名前で読み込んでいます。
「np」のとこは自分の好きな名前で大丈夫ですが、numpyはnpって省略して呼ぶのがベストな気がします。
2行目は、xをnumpy配列で初期化しています。
2次元配列で初期化していますね。
ちなみに配列は英語で「array」です。
3行目は、print関数を用いてxを表示しています。
文字列中に配列などの変数を埋め込むために使うのがformat関数です。
文字列”x:\n{}”中の{}のとこに配列xの中身が表示されるわけです。
format関数は無くても良いのですが、表示結果を綺麗にしてくれるので当ブログでは頻繁に使います。
ちなみに文字列”\n”は改行を表します。
出力結果を見ると、ちゃんと「x:」と配列の間が改行されていますよね。
SciPy
SciPyもPythonで科学技術計算をする際の基本的なツールの1つです。
機能はNumpyをほぼ網羅していて、より高度な数学計算が可能です。
ちなみに読み方は「サイパイ」が主流です。
SciPyの使用例
SciPyを用いて疎行列を表現することが多く、「scipy.sparse」っていうメソッドを使います。ちなみにsparseは疎って意味です。
疎行列は、行列の成分がほとんど0になっている行列をコンパクトに格納するための行列です。
これはメモリを無駄に使わないための賢い戦略です。
疎行列は色んな種類があるのですが、CSR形式とCOO形式が有名です。覚えなくて大丈夫です。
「CSRとかCOOっていう疎行列があるらしい」ぐらいで覚えとこう。
それでは使用例を説明します。
import numpy as np
from scipy import sparse
# Create a 2D NumPy array with a diagonal of ones, and zeros everywhere else
eye = np.eye(4)
print("NumPy array:\n{}". format(eye))
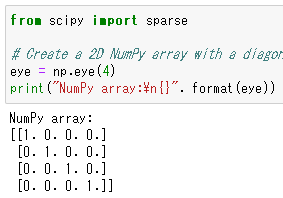
1行目は、numpyライブラリを「np」っていう名前で読み込んでいます。
これは先述したNumPyのとこでもやりましたね。
すでに読み込んでいれば書かなくても大丈夫です。
2行目は、scipyライブラリからsparseライブラリを読み込んでいます。
4行目は、コメントなので気にしなくていいです。英語読める人は読んでおけです。
5行目は、対角成分が1でそれ以外が0の2次元numpy配列を「eye」っていう名前で作っています。
eye関数は単位行列を作る関数です。
6行目はprint関数でeyeを表示しています。
# Convert the NumPy array to a SciPy sparse matrix in CSR format
# Only the nonzero entries are stored
sparse_matrix = sparse.csr_matrix(eye)
print("\nSciPy sparse CSR matrix:\n{}". format(sparse_matrix))
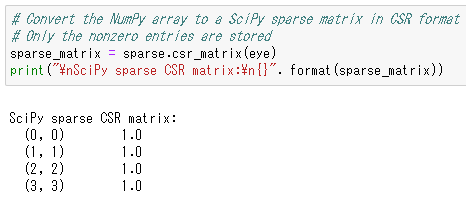
3行目は、Numpy配列をSciPyのCSR形式の疎行列に変換しています。
4行目は、変換後のsparse_matrixっていう疎行列を表示しています。
出力結果を見ると、numpy配列の(0, 0)成分が1.0、(1, 1)成分が1.0という感じで非ゼロの要素だけを抽出していることがわかります。
このように疎行列は非ゼロを無視することでメモリを節約する役割があるんですね。
data = np.ones(4)
row_indices = np.arange(4)
col_indices = np.arange(4)
eye_coo = sparse.coo_matrix((data, (row_indices, col_indices)))
print("COO representation:\n{}". format(eye_coo))
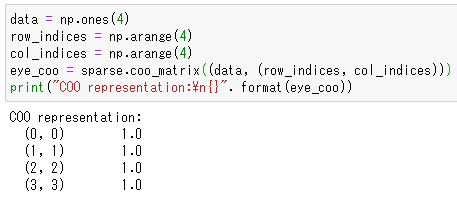
1行目は、全ての要素がすべて1の配列を初期化しています。この配列は非ゼロではない要素のみを抽出したデータなので、単位行列eye(4)を別の形で表現した配列と思ってもらって大丈夫です。
なるほどね、完全に理解した()
2行目と3行目は、列と行の非ゼロ要素の番号を格納しています。arrange関数は連番で数字を作ってくれる関数です。
5行目は、疎行列を表示しています。出力を見ると、CSR形式と同じ形ですね。
疎行列は非ゼロを無視することでメモリを節約してくれてるっていう理解だけで良いです。
matplotlib
matplotlibはPythonのグラフ描画ライブラリです。機械学習に限らず、開発者らに非常によく使われます。しみしんも大学院の研究でお世話になりました。
matplotlibの使用例
sin関数を可視化します。
%matplotlib inline import matplotlib.pyplot as plt # Generate a sequence of numbers from -10 to 10 with 100 steps in between x = np.linspace(-10, 10, 100) # Create a second array using sine y = np.sin(x) # The plot function makes a line chart of one array against another plt.plot(x, y, marker="x")
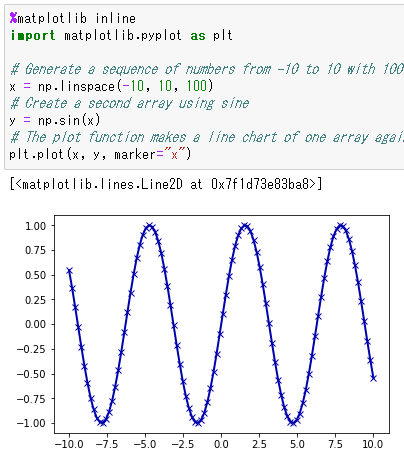
1行目は、グラフをブラウザ上に描画するための宣言です。
2行目は、プロットに必要なライブラリを「plt」という名前で読み込んでいます。
5行目は、プロットする点のx座標配列に-10~10で等間隔に100個の数字を格納しています。
7行目は、プロットする点のy座標配列ににsin関数の数値を格納しています。
9行目は、グラフに描画する関数を使っています。
makerでプロットの形をxマークに指定してしています。
pandas
pandasは、データを変換したり解析したりするためのライブラリです。エクセルの表を読み込んだり、表のデータをいじったりできる機能があります。
pandasの使用例
import pandas as pd
# create a simple dataset of people
data = {'Name': ["John", "Anna", "Peter", "Linda"],
'Location' : ["New York", "Paris", "Berlin", "London"],
'Age' : [24, 13, 53, 33]
}
data_pandas = pd.DataFrame(data)
# IPython.display allows "pretty printing" of dataframes
# in the Jupyter notebook
display(data_pandas)
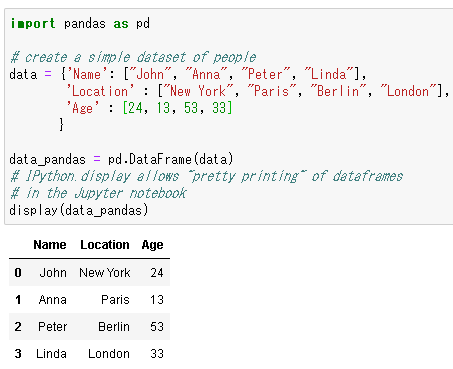
1行目は、pandasライブラリを「pd」という名前で読み込んでいます。
4~7行目は、表を作成しています。カテゴリは名前と場所と年齢です。
9行目は、pandasライブラリのDataFrameメソッドを使ってdataを表にします。
12行目は、display関数を用いて表を表示しています。
mglearn
グラフ描画やデータ読込でソースコードがぐちゃぐちゃにならないようにするためのライブラリです。
「Pythonではじめる機械学習」の著者が作成したライブラリなので、Anacondaには入っていません。
別途でインストールする必要があり、GitHubのここから入手できます。
プログラミングに詳しい人は、pipコマンドでインストールしても大丈夫です。
「mglearnなんてインストールしたくない!」という人は、インストールしなくて済む方法を紹介している以下の記事を参照してください。pipよりおススメです。

以上で、本ブログの「Pythonで機械学習」で使用するライブラリの説明は終わりです。
用語が沢山出てきて一度で覚えられはしないと思いますが、忘れたらここに戻ってきて思い出せばおけです。
参考図書
本記事はこちらの本を参考にしています。





コメント