
以前の記事では、教師あり学習はクラス分類と回帰があると言いました。
今回はpythonで教師あり学習のクラス分類を実装しましょう。
本記事を読めば、データさえ揃えば実世界でもクラス分類ができるようになります。
使用するデータなどのプログラミング環境については、以前の記事を参照してくださいね。

今回実装するクラス分類アルゴリズムは、k-最近傍法(k-NN)です。
k-最近傍法とは
k-最近傍法は最も単純な学習アルゴリズムであると言われています。モデルの構築は、学習データを空間上にプロットしておくだけ!未知のデータがプロットされたら、近いk個の点で投票を行いクラスを推定します。
何はともあれ、とりあえず手を動かして動きを確認します。
k-最近傍法の動きを確認しよう
データをプロットしてみる
まずはJupyter NotebookでPython3のファイルを作成しましょう。
ここではmglearnライブラリに含まれるforgeっていう2クラス分類用の人工データを使います。
まずはforgeの中身を見てみましょう。
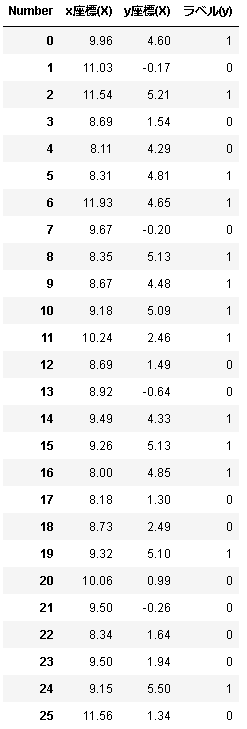
大文字Xには入力である座標データを、小文字yにはラベルデータを格納します。
%matplotlib inline from preamble import * X, y = mglearn.datasets.make_forge() col=pd.Index(['x座標(X)','y座標(X)'],name='Number') df_x=pd.DataFrame(X,columns=col) df_x['ラベル(y)']=y df_x
1行目でmatplotlibライブラリ使うぞ宣言してます。
2行目で必要なライブラリを一気にimportするおまじないをしてます。
4行目でデータを読み込んでます。Xに入力データ、yにラベルを格納します。都合上mglearnライブラリを使ってますけど、通常はエクセルとかからデータを持ってくると思います。
5行目で表のラベルを作ってます。
6行目でDataFrameメソッド使って表を作ってます。
7行目でyのデータを追加で挿入してます。なんか汚いですねすみません(笑)
8行目で表を出力です。
forgeは上記のように26個の座標と2種類のラベル(0 or 1)のデータで構成されてます。
ちなみに上の表はPandasライブラリを使って表示してます。ソースコードのpdってやつです。綺麗ですよね。
とりあえずプロットしてみましょう。以下を入力してshift+enterです!
# plot dataset
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.legend(["Class 0", "Class 1"], loc=4)
plt.xlabel("First feature")
plt.ylabel("Second feature")
print("X.shape:", X.shape)
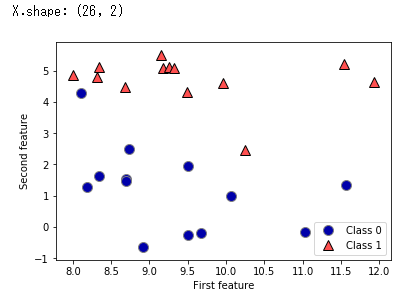
2行目でデータをプロットしています。discrete_scatter()は第1引数にx座標,第2引数にy座標,第3引数にラベルを渡すとプロットしてくれる関数です。データXは(x座標,y座標)という構造になっていて、X[:,0]は全てのデータのx座標,X[:,1]は全てのデータのy座標を表します。
3行目は凡例を表示するlegend関数を使っています。loc=4は右下に表示してくれるパラメータです。数字変えたら多分位置変わります。
4,5行目では軸ラベル名を設定してます。
6行目ではshapeメソッドを使ってデータの大きさを表示させてます。
出力結果を見ると、forgeは2つの特徴量(ラベル)を持つ26個のデータということがわかります。
k-最近傍法の動きを確認
mglearnライブラリを用いて、k-最近傍法をなんとなく動かしてみます。
以下を入力してshift+enterです。このソースコードは実用性がないので覚えなくて大丈夫です。あくまでk-最近傍法の動作確認。
mglearn.plots.plot_knn_classification(n_neighbors=3)
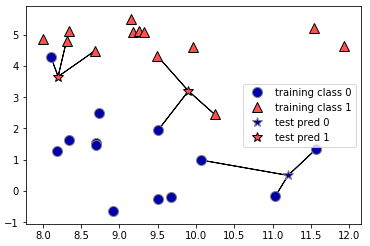
mglearnライブラリを用いて未知のデータを星マークとしてプロットし、3-最近傍法を使ってます。
星マークに近い3つを選び、投票でラベルを決定しています。つまり、近い3点のうち最もよく出現するラベルにするってことですね。
では次はscikit-learnを使って本格的にk-最近傍法を実装しましょう。
クラス分類器を実装!性能を評価しよう
scikit-learnライブラリを使ってデータを訓練データとテストデータに分け、クラス分類モデルを構築して汎化性能を評価しましょう。
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train, y_train)
print("Test set predictions:", clf.predict(X_test))
出力結果
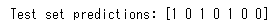
1行目でscikit-learnのtrain_testsplit関数を使いたいです宣言しときます。
2行目でforgeデータを読み込みます。
3行目で訓練データとテストデータを75%,25%の割合で分割しています。割合は指定できると思いますが、デフォルトだと75%,25%なのでしょう。
5行目でK-最近傍法を使いたい宣言して、
6行目でclfというインスタンスに3-最近傍法を設定しておきます。インスタンス名は何でも大丈夫です。
7行目でfitメソッドで訓練セットを用いてクラス分類器を訓練します。
8行目でpredictメソッドでテストデータに対して予測を行います。その結果をprint関数で表示しているわけですね。
それでは汎化性能を評価します。scoreメソッドを使うと楽に評価できます。
print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test)))
出力結果
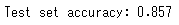
精度は86%ということなので、このクラス分類器はテストデータのうち86%に対して正しくクラスを予測したということです。
まとめ
最初にk-最近傍法の動きを確認した後、scikit-learnライブラリを使ってクラス分類を実装しました。
このように教師あり学習では、正解の分かるデータを訓練データとテストデータに分割して評価を行いながら理想的な機械学習モデルを構築していきます。訓練データが少なすぎても多すぎても未知のデータに対する予測精度は下がってしまいます。
scikit-learnでは今回実装したk-最近傍法以外にも様々なクラス分類器が使用できるので試してみると良いと思います。
ちなみに、k-最近傍法は処理速度が遅くて大規模なデータには扱えないから実際にはあまり使われていないので、他のクラス分類器も勉強してみると良いです。
- 教師あり機械学習を実装するときは、データを訓練データとテストデータに分ける
- fitメソッドで学習
- predictメソッドで予測
参考図書
ちなみにこの記事は↓の本を参考にしています。






コメント